Speech Synthesis (TTS)
With Omni Automation, communication with the user of automation tools is accomplished through user-generated dialogs and plug-in UI interfaces, as well as aurally through the device built-in Speech Synthesis frameworks. Omni Automation scripts and plug-ins can “talk” in order to pass important information to the user.
The following documentation details how to incorporate text-to-speech to your automation script and plug-ins.
CLASSES: Speech.Voice | Speech.Utterance | Speech.Synthesizer
Speech.Voice Class
The fundamental object in Text-to-Speech in the instance of the Speech.Voice class that is used to render and convey the specified text message to the user.
NOTE: On macOS, the default voice options are set in the Spoken Content section of the Accessibility system preference pane. On iPadOS and iOS, the default voice options are set in the Speech section of the VoiceOver preference in the Settings app.
Class Properties
allVoices (Array of Speech.Voice r/o) • An array of all of the currently installed voice instances.
currentLanguageCode (String r/o) • The language code for the current default voice.
All Voice Instances
Speech.Voice.allVoices//--> [[object Speech.Voice], [object Speech.Voice], [object Speech.Voice], [object Speech.Voice], [object Speech.Voice], [object Speech.Voice], [object Speech.Voice], [object Speech.Voice], [object Speech.Voice], [object Speech.Voice], …] (75)
Current Language Code
Speech.Voice.currentLanguageCode//--> "en-US"
Instance Properties
gender (Speech.Voice.Gender r/o) • The gender of the voice.
identifier (String r/o) • The unique identifier string of the voice.
language (String r/o) • The language code for the voice.
name (String r/o) • The name of the voice, such as “Sammantha”
quality (Speech.Voice.Quality r/o) • The quality of the voice. IMPORTANT: Due to system Speech API issues, this property is currently non-functioning.
Voice Objects Matching the Current Language
var languageCode = Speech.Voice.currentLanguageCodevoices = Speech.Voice.allVoices.filter(voice => {if(voice.language === languageCode){return voice}})voices.map(voice => voice.name)
Speech.Voice.Gender Class
Female (Speech.Voice.Gender r/o) • Speech.Voice.Gender.Female
Male (Speech.Voice.Gender r/o) • Speech.Voice.Gender.Male
Unspecified (Speech.Voice.Gender r/o) • Speech.Voice.Gender.Unspecified
all (Array of Speech.Voice.Gender r/o) • [Speech.Voice.Gender.Female, Speech.Voice.Gender.Male, Speech.Voice.Gender.Unspecified] This property is used in creating plug-in forms
Speech.Voice.Quality Class
Default (Speech.Voice.Quality r/o) • Speech.Voice.Quality.Default
Enhanced (Speech.Voice.Quality r/o) • Speech.Voice.Quality.Enhanced
all (Array of Speech.Voice.Quality r/o) • [Speech.Voice.Quality.Default, Speech.Voice.Quality.Enhanced] This property is used in creating plug-in forms.
Class Functions
withLanguage(code: String or null) → (Speech.Voice or null) • Returns a voice for the given BCP–47 language code (such as en-US or fr-CA), or the default voice if passed null. Returns null for an invalid langauge code.
withIdentifier(identifier: String) → (Speech.Voice or null) • Returns the voice with the given identifier, or null if not found.
You can use the currentLanguageCode property to derive the default voice for the current language:
Default Voice for Current Language
Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode)//--> [object Speech.Voice] {gender: [object Speech.Voice.Gender: Unspecified], identifier: "com.apple.voice.compact.en-US.Samantha", language: "en-US", name: "Samantha"}
IMPORTANT: With the latest versions of iOS · iPadOS · macOS · visionOS the default voice returned by the withLanguage function is the currently user-selected voice found in the Accessibility > Spoken Content > Voices system preference. The initial default value for U.S. English is usually: “Samantha”
The “Alex” Voice
While the “Alex” voice is installed on all platforms, the identifier of the “Alex” voice changes depending on platform, and so a conditional statement must use the value of the platformName property do determine which ID to use:
IMPORTANT: The Alex voice is the only voice installed on all Apple devices that supports the use of embedded TTS commands, such as: [[SLNC 500]]
The “Alex” Voice
deviceOS = app.platformNameAlexID = ((deviceOS === "macOS" || deviceOS === "visionOS") ?"com.apple.speech.synthesis.voice.Alex" :"com.apple.speech.voice.Alex")voiceObj = Speech.Voice.withIdentifier(AlexID)
In the case of the Alex voice, a simple single-line solution for getting the corresponding voice object is to use the find() function with a startsWith() or endsWith()condition:
Alex: Single-Line Solution
voiceObj = Speech.Voice.allVoices.find(voice => voice.name.startsWith("Alex"))
Alex: Single-Line Solution
voiceObj = Speech.Voice.allVoices.find(voice => voice.identifier.endsWith("Alex"))
Note the differences in the resulting Alex voice objects:
Result: macOS
//--> macOS: [object Speech.Voice] {gender: [object Speech.Voice.Gender: Male], identifier: "com.apple.speech.synthesis.voice.Alex", language: "en-US", name: "Alex", quality: [object Speech.Voice.Quality]}
Result: iPadOS/iOS
//--> iPadOS/iOS: [object Speech.Voice] {gender: [object Speech.Voice.Gender: Unspecified], identifier: "com.apple.speech.voice.Alex", language: "en-US", name: "Alex", quality: [object Speech.Voice.Quality: Enhanced]}
Here’s a function for creating utterances using the Alex voice regardless of the current device:
The “Alex” Function
function createUtterance(textToSpeak){deviceOS = app.platformNameAlexID = ((deviceOS === "macOS" || deviceOS === "visionOS" ) ?"com.apple.speech.synthesis.voice.Alex" :"com.apple.speech.voice.Alex")voiceObj = Speech.Voice.withIdentifier(AlexID)voiceRate = 0.5utterance = new Speech.Utterance(textToSpeak)utterance.voice = voiceObjutterance.rate = voiceRatereturn utterance}
And a version of the Alex function that uses the default language voice if Alex is not installed:
The “Alex” Function (Alternative)
function createUtterance(textToSpeak){deviceOS = app.platformNameAlexID = ((deviceOS === "macOS" || deviceOS === "visionOS" ) ?"com.apple.speech.synthesis.voice.Alex" :"com.apple.speech.voice.Alex")voiceObj = Speech.Voice.withIdentifier(AlexID)if(!voiceObj){voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode)console.error("Alex voice is not installed.")}utterance = new Speech.Utterance(textToSpeak)utterance.voice = voiceObjutterance.rate = Speech.Utterance.defaultSpeechRatereturn utterance}
Checking Voices
Is Voice Installed? (Check by Name)
voiceName = "Serena"voiceNames = Speech.Voice.allVoices.map(voice => voice.name)voiceStatus = voiceNames.includes(voiceName)//--> true (installed) or false (not installed)
Is Voice Installed? (Check by ID)
voiceID = "com.apple.speech.synthesis.voice.serena.premium"voiceIDs = Speech.Voice.allVoices.map(voice => voice.identifier)voiceStatus = voiceIDs.includes(voiceID)//--> true (installed) or false (not installed)
Is Voice Installed?
voiceID = "com.apple.speech.synthesis.voice.serena.premium"voiceIDs = Speech.Voice.allVoices.map(voice => voice.identifier)if (voiceIDs.includes(voiceID){//--> voice is installed, perform actions} else {throw "The required voice is not installed."}
Return voice object for a voice by name, and if it doesn't exist, use the Alex voice instead:
Find Voice Object by Name (begins with…)
voiceName = "Serena"voiceObj = Speech.Voice.allVoices.find(voice => voice.name.startsWith(voiceName))if (!voiceObj){voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) }
Find Voice Object by Identifer (includes name)
voiceName = "Serena"voiceObj = Speech.Voice.allVoices.find(voice => voice.identifier.includes(voiceName))if (!voiceObj){voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) }
Sorting Voices by Name
voices = Speech.Voice.allVoicesvoices.sort((a, b) => {var x = a.name;var y = b.name;if (x < y) {return -1;}if (x > y) {return 1;}return 0;})voiceNames = voices.map(task => {return task.name})
Speech.Utterance Class
An instance of the Speech.Utterance class contains the text and voice properties to be rendered by an instance of the Speech.Synthesizer class.
Class Properties
defaultSpeechRate (Number r/o)
maximumSpeechRate (Number r/o)
minimumSpeechRate (Number r/o)
Utterance Class Speech Rate Properties
console.log("defaultSpeechRate", Speech.Utterance.defaultSpeechRate)//--> 0.5console.log("maximumSpeechRate", Speech.Utterance.maximumSpeechRate)//--> 1console.log("minimumSpeechRate", Speech.Utterance.minimumSpeechRate)//--> 0
Constructor
new Speech.Utterance(string: String) → (Speech.Utterance) • Creating a new instance of the Speech.Utterance class.
Instance Properties
pitchMultiplier (Number) • A value between 0.5 and 2.0, controlling the picth of the utterance.
postUtteranceDelay (Number) • The number of seconds to pause after the utterance is rendered.
preUtteranceDelay (Number) • The number of seconds to pause before the utterance is rendered.
prefersAssistiveTechnologySettings (Boolean) • If an assistive technology is on, like VoiceOver, the user’s selected voice, rate and other settings will be used for this speech utterance instead of the default values. If no assistive technologies are on, then the values of the properties on AVSpeechUtterance will be used. Note that querying the properties will not refect the user’s settings.
rate (Number) • A value between Speech.Utterance.minimumSpeechRate and Speech.Utterance.maximumSpeechRate controlling the rate of speech for the utterance.
string (String or null r/o) • The text to be rendered to speech.
voice (Speech.Voice or null) • The voice to use for this utterance, or null in which case the default voice will be used.
volume (Number) • A value between 0.0 and 1.0 controller the volume of the utterance.
Speak Utterance
string = "The rain in Spain falls mainly on the plain."utterance = new Speech.Utterance(string)voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) utterance.voice = voiceObjnew Speech.Synthesizer().speakUtterance(utterance)
The following example creates and vocalizes an array of utterances with a 1-second pause appended to each utterance:
Speak List of Strings
var voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) strings = ["January", "February", "March", "April", "May", "Jume", "July", "August", "September", "October", "November", "December"]utterances = new Array()strings.forEach(string => {utterance = new Speech.Utterance(string)utterance.voice = voiceObjutterance.postUtteranceDelay = 1utterances.push(utterance)})var synthesizer = new Speech.Synthesizer()utterances.forEach(utterance => {synthesizer.speakUtterance(utterance)})
TIP: In the example above, use Math.random() as the value for the postUtteranceDelay property to have the computer randomly add a delay value between 0 and 1.
Add the following function to your scripts to have it create utterances using the default voice for the current language.
Function for Creating Utterances
function createUtterance(textToSpeak){langCode = Speech.Voice.currentLanguageCodevoiceObj = Speech.Voice.withLanguage(langCode)utterance = new Speech.Utterance(textToSpeak)utterance.voice = voiceObjutterance.rate = Speech.Utterance.defaultSpeechRatereturn utterance}
IMPORTANT: Due to system Speech API issues, the prefersAssistiveTechnologySettings property currently does not work as expected.
The Assistive Settings Property
utteranceString = "The quick brown fox jumped over the lazy dog."utterance = new Speech.Utterance(utteranceString)utterance.prefersAssistiveTechnologySettings = truesynthesizer = new Speech.Synthesizer()synthesizer.speakUtterance(utterance)
Speech.Synthesizer Class
The Speech.Synthesizer class represents the code object for speaking the provided text (utterance).
Instance Functions
speakUtterance(utterance: Speech.Utterance) • Enqueues the utterance. If the utterance is already or enqueued or speaking, throws an error.
stopSpeaking(boundary: Speech.Boundary) → (Boolean) • Stop the Speech.Synthesizer instance.
pauseSpeaking(boundary: Speech.Boundary) → (Boolean) • Pause the Speech.Synthesizer instance.
continueSpeaking() → (Boolean) • Continue speaking the paused utterance.
Instance Properties
paused (Boolean r/o) • The speech synthesizer instance is paused.
speaking (Boolean r/o) • The speech synthesizer instance is speaking.
Speech.Boundary Class
Immediate (Speech.Boundary r/o) • Speech.Boundary.Immediate
Word (Speech.Boundary r/o) • Speech.Boundary.Word
all (Array of Speech.Boundary r/o) • This property is used in the creation of plug-in forms.

Stopping the Speech Synthesizer
voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) messageString = "Once upon a time in a village far far away, lived a man and his dog. Every day the man and the dog would walk the beach, looking for driftwood."utterance = new Speech.Utterance(messageString)utterance.voice = voiceObjsynthesizer = new Speech.Synthesizer()synthesizer.speakUtterance(utterance)alert = new Alert("Text-to-Speech", "Click “Stop” button to stop speaking.")alert.addOption("Continue")alert.addOption("Stop")alert.show().then(index => {console.log(index)if(index === 1){synthesizer.stopSpeaking(Speech.Boundary.Word)}})
Another example of stopping an active speech synthesizer, using interaction with a notification alert:
Stopping Speech Synthesizer via Notification
string = "Once upon a time in a village far far away lived a man and his dog. Every day the man and the dog would walk the beach looking for driftwood. On occasion, they would find branches washed up upon the shore, gnarled and twisted in their beauty."utterance = new Speech.Utterance(string)utterance.rate = Speech.Utterance.defaultSpeechRatevoiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode)utterance.voice = voiceObjvar synthesizer = new Speech.Synthesizer()synthesizer.speakUtterance(utterance)notification = new Notification("Speaking…")notification.subtitle = "(TAP|CLICK to Stop)"notification.show().then(notif => {synthesizer.stopSpeaking(Speech.Boundary.Word)}).catch(err => {synthesizer.stopSpeaking(Speech.Boundary.Word)})
The following example script, will open the Text-to-Speech section of the System Preferences application and speak the error message if the voice, identified by the value of its name property, is not installed.
Check for Specified Voice
// CHECK FOR VOICE BY NAMEvoiceName = "Serena"voiceObj = Speech.Voice.allVoices.find(voice => {return voice.name === voiceName})if (voiceObj){var messageString = `Hello, I am the text-to-speech voice “${voiceName}.”`} else {voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode)var messageString = `The text-to-speech voice “${voiceName}” is not installed.`}utterance = new Speech.Utterance(messageString)utterance.voice = voiceObjutterance.rate = 0.5synthesizer = new Speech.Synthesizer()synthesizer.speakUtterance(utterance)
Voice Tester Plug-In
The voices installable using the Apple Text-to-Speech preferences respond differently to rate adjustments. The following plug-in presents controls for choosing the high-quality voice and the rate so you can find the rate adjustment that works best for the chosen voice.
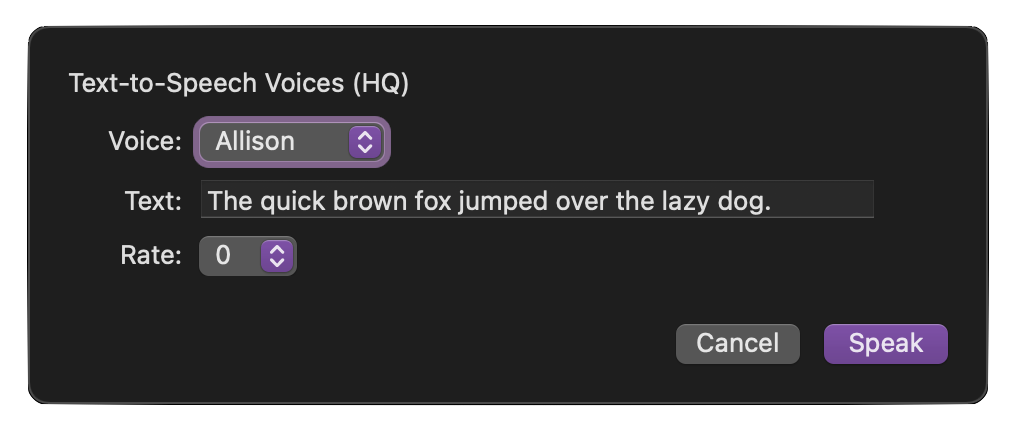
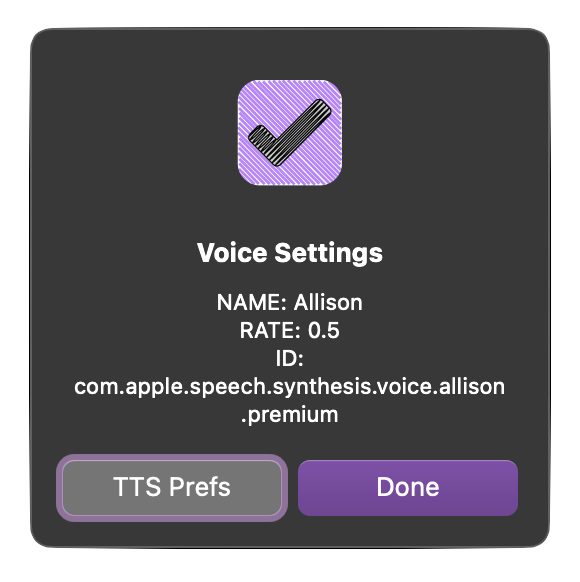
Voice Tester Plug-In
/*{"author": "Otto Automator","targets": ["omnioutliner","omnifocus","omniplan","omnigraffle"],"type": "action","identifier": "com.omni-automation.tts.speech-form","version": "1.6","description": "Displays a form for setting the parameters of a chosen voice. Results are logged in the console.","label": "Voice Tester","shortLabel": "Voice Tester","mediumLabel": "Voice Tester","longLabel": "Voice Tester","paletteLabel": "Voice Tester","image": "person.wave.2.fill"}*/(() => {const action = new PlugIn.Action(async function(selection){form = new Form();voices = Speech.Voice.allVoicesif(app.platformName === "macOS"){// on macOS, Alex is not included by defaultalexVoice = Speech.Voice.withIdentifier("com.apple.speech.synthesis.voice.Alex")voices.unshift(alexVoice)}voices.sort((a, b) => {var x = a.name;var y = b.name;if (x < y) {return -1;}if (x > y) {return 1;}return 0;})voiceNames = voices.map(task => {return task.name})voice = new Form.Field.Option("voice","Voice",voices,voiceNames,voices[0])form.addField(voice)defaultString = "The quick brown fox jumped over the lazy dog."utterance = new Form.Field.String("utteranceString","Text",defaultString)form.addField(utterance)displayRates = ["+5", "+4", "+3", "+2", "+1", "0", "-1", "-2", "-3", "-4", "-5"]rates = ["1.0", "0.9", "0.8", "0.7", "0.6", "0.5", "0.4", "0.3", "0.2", "0.1", "0"]rate = new Form.Field.Option("rate","Rate",rates,displayRates,"0.5")form.addField(rate)form.validate = function(formObject){textValue = formObject.values['utteranceString']return (textValue && textValue.length > 0) ? true:false}title = "Text-to-Speech Voices (HQ)"button = "Speak"formObject = await form.show(title, button)voiceObj = formObject.values["voice"]name = voiceObj.nameid = voiceObj.identifierlang = voiceObj.languageif(app.platformName === "macOS"){var intro = `Hello, my name is ${name}.`} else {var intro = `Hello, my name is ${name}.`}utteranceString = intro + formObject.values["utteranceString"]utterance = new Speech.Utterance(utteranceString)rateAmt = parseFloat(formObject.values["rate"])utterance.rate = rateAmtutterance.voice = voiceObjsynthesizer = new Speech.Synthesizer()synthesizer.speakUtterance(utterance)console.log("NAME:", name, "RATE:", rateAmt, "ID: ", id)alert = new Alert("Voice Settings", `NAME: ${name}\nLANGUAGE: ${lang}\nRATE: ${rateAmt}\nID: ${id}`)alert.addOption("Done")if(app.platformName === "macOS"){alert.addOption("TTS Prefs")}alert.show(index => {if(app.platformName === "macOS" && index === 1){// on macOS, open system preference for text-to-speechurlStr = "x-apple.systempreferences:com.apple.preference.universalaccess?TextToSpeech"URL.fromString(urlStr).open()}})});return action;})();
IMPORTANT: Voices added using the System Text-to-Speech preferences will not be available until the host Omni application is quit and restarted.
Examples
Examples using the Speech classes.
The first example uses the Formatter.Date class to speak the current time and date:
What is the Current Time and Date?
dateString = Formatter.Date.withFormat('h:mma, EEEE, LLLL d').stringFromDate(new Date()//--> "12:07AM, Wednesday, March 2")utterance = new Speech.Utterance(`It is ${dateString}`)speakerVoice = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode)utterance.voice = speakerVoicenew Speech.Synthesizer().speakUtterance(utterance)
| Tasks Due Today |
| An OmniFocus plug-in that aurally lists the available tasks that are due today. |
|
|
OmniFocus: Tell Me Tasks Due Today
/*{"type": "action","targets": ["omnifocus"],"author": "Otto Automator","identifier": "com.omni-automation.of.tts.tasks-due-today","version": "2.1","description": "Uses the Speech API of Omni Automation to speak the names and due times of the tasks due today, in the order they are due.","label": "Tasks Due Today","shortLabel": "Tasks Due","paletteLabel": "Tasks Due","image": "rectangle.3.group.bubble.left.fill"}*/(() => {const action = new PlugIn.Action(function(selection, sender){// FUNCTION FOR ORDINAL STRINGS: 1st, 2nd, 3rd, 4th...function ordinal(n) {var s = ["th", "st", "nd", "rd"];var v = n%100;return n + (s[(v-20)%10] || s[v] || s[0]);}// GLOBAL VOICEspeakerVoice = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) // CURRENT TIME AND DATEdate = new Date()currentDateTimeString = Formatter.Date.withFormat('h:mma, EEEE, LLLL d').stringFromDate(date) //--> "12:07AM, Wednesday, March 2" (Speech API adds ordinal dates when spoken)openingUtterance = new Speech.Utterance(`It is ${currentDateTimeString}`) openingUtterance.postUtteranceDelay = 0.5openingUtterance.voice = speakerVoice// IDENTIFY TASKS DUE TODAYfmatr = Formatter.Date.withStyle(Formatter.Date.Style.Short)rangeStart = fmatr.dateFromString('today')rangeEnd = fmatr.dateFromString('tomorrow')tasksToProcess = flattenedTasks.filter(task => {return (task.effectiveDueDate > rangeStart &&task.effectiveDueDate < rangeEnd &&task.taskStatus === Task.Status.DueSoon)})// PROCESS DUE TASK(S)if(tasksToProcess.length === 0){string = "There are no available tasks due today."utterance = new Speech.Utterance(string)utterance.voice = speakerVoicevar utterances = [openingUtterance, utterance]var tasksFound = false} else {// SORT BY TIME DUEvar tasksFound = truetasksToProcess.sort((a, b) => {var x = a.effectiveDueDate;var y = b.effectiveDueDate;if (x < y) {return -1;}if (x > y) {return 1;}return 0;})// TASK(S) DUE ANNOUNCEMENTtaskCount = String(tasksToProcess.length)if(taskCount === "1"){var textSegments = ["There is one task due today."]var alertTitle = "1 Task Due Today"} else {var textSegments = [`There are ${taskCount} tasks due today.`]var alertTitle = `${taskCount} Tasks Due Today`}// CREATE INFO STRING FOR EACH TASKvar timeFormatter = Formatter.Date.withFormat('h:mma')tasksToProcess.forEach((task, index) => {taskName = task.namedueDateObj = task.effectiveDueDatedueTimeString = timeFormatter.stringFromDate(dueDateObj)spokenOrdinalNumber = ordinal(index + 1)parentObj = task.parentif(parentObj){parentProject = parentObj.projectparentName = parentObj.nameparentType = (parentObj.project) ? "project" : "task"var TTString = `The ${spokenOrdinalNumber} task, ${taskName}, of ${parentType} ${parentName}, is due at ${dueTimeString}.`} else {var TTString = `The ${spokenOrdinalNumber} task, ${taskName}, is due at ${dueTimeString}.`}textSegments.push(TTString)})// CREATE UTTERANCE FOR EACH TASKutterances = [openingUtterance]textSegments.forEach(string => {utterance = new Speech.Utterance(string)utterance.voice = speakerVoiceutterance.rate = Speech.Utterance.defaultSpeechRateutterance.postUtteranceDelay = 0.5utterances.push(utterance)})}// USE SPEECH API TO SPEAK UTTERANCESsynthesizer = new Speech.Synthesizer()utterances.forEach(utterance => {synthesizer.speakUtterance(utterance)})if(tasksFound){alert = new Alert(alertTitle, "Click “Done” button to stop speaking.")alert.addOption("Done")alert.show().then(index => {synthesizer.stopSpeaking(Speech.Boundary.Word)})}});action.validate = function(selection, sender){return true};return action;})();
Audio and Spoken Alerts
Here’s an example of using both audio and spoken alerts. In this example, an alert sound is played and an alert message spoken if the script user has not previously selected a single task or project:
Spoken and Audio Alerts (OmniFocus)
sel = document.windows[0].selectionselCount = sel.tasks.length + sel.projects.lengthif(selCount === 1){if (sel.tasks.length === 1){var selectedItem = sel.tasks[0]} else {var selectedItem = sel.projects[0]}// SELECTION PROCESSING} else {if(app.platformName === "macOS"){Audio.playAlert()}alertMessage = "Please select a single project or task."utterance = new Speech.Utterance(alertMessage)voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode)utterance.voice = voiceObjnew Speech.Synthesizer().speakUtterance(utterance)}
Read Note of Selected Project|Task
A script for OmniFocus.
Read Note of Selected Project|Task
sel = document.windows[0].selectionselCount = sel.tasks.length + sel.projects.lengthfunction createUtterance(textToSpeak){voiceObj = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) voiceRate = 0.4utterance = new Speech.Utterance(textToSpeak)utterance.voice = voiceObjutterance.rate = voiceRatereturn utterance}var synthesizer = new Speech.Synthesizer()if(selCount === 1){if (sel.tasks.length === 1){var selectedItem = sel.tasks[0]var objType = "task"} else {var selectedItem = sel.projects[0]var objType = "project"}noteString = selectedItem.noteobjectName = selectedItem.nameif(noteString && noteString.length > 0){utterance = createUtterance(noteString)alert = new Alert(`“${objectName}” Note`, "Press “Done” to Stop.")alert.addOption("Done")synthesizer.speakUtterance(utterance)alert.show().then(index => {synthesizer.stopSpeaking(Speech.Boundary.Word)})} else {alertMessage = `The ${objType} “${objectName}” does not have any note text.`utterance = createUtterance(alertMessage)synthesizer.speakUtterance(utterance)new Alert("No Note", alertMessage).show()}} else {if(app.platformName === "macOS"){Audio.playAlert()}alertMessage = "Please select a single project or task."utterance = createUtterance(alertMessage)synthesizer.speakUtterance(utterance)}
The Declaration of Independence
An example of how to create a stoppable vocalization of a long document:
Creating a Longer Vocalization
// THE STRINGS (SENTENCES) TO BE SPOKENstrings = ["When in the Course of human Events, it becomes necessary for one People to dissolve the Political Bands which have connected them with another, and to assume among the Powers of the Earth, the separate and equal Station to which the Laws of Nature and of Nature’s God entitle them, a decent Respect to the Opinions of Mankind requires that they should declare the causes which impel them to the Separation.", "We hold these Truths to be self-evident, that all Men are created equal, that they are endowed by their Creator with certain unalienable Rights, that among these are Life, Liberty and the Pursuit of Happiness — That to secure these Rights, Governments are instituted among Men, deriving their just Powers from the Consent of the Governed, that whenever any Form of Government becomes destructive of these Ends, it is the Right of the People to alter or to abolish it, and to institute new Government, laying its Foundation on such Principles, and organizing its Powers in such Form, as to them shall seem most likely to effect their Safety and Happiness.", "Prudence, indeed, will dictate that Governments long established should not be changed for light and transient Causes; and accordingly all Experience hath shewn, that Mankind are more disposed to suffer, while Evils are sufferable, than to right themselves by abolishing the Forms to which they are accustomed.", "But when a long Train of Abuses and Usurpations, pursuing invariably the same Object, evinces a Design to reduce them under absolute Despotism, it is their Right, it is their Duty, to throw off such Government, and to provide new Guards for their future Security. Such has been the patient Sufferance of these Colonies; and such is now the Necessity which constrains them to alter their former Systems of Government."]// CREATE UTTERENCES FOR EACH STRINGnarrator = Speech.Voice.withLanguage(Speech.Voice.currentLanguageCode) utterances = new Array()strings.forEach(string => {utterance = new Speech.Utterance(string)utterance.voice = narratorutterance.postUtteranceDelay = 1utterances.push(utterance)})// CREATE SPEECH SYNTHESIZER INSTANCEsynthesizer = new Speech.Synthesizer()// BEGIN SPEAKINGutterances.forEach(utterance => {synthesizer.speakUtterance(utterance)})// SHOW ALERTalert = new Alert("The Declaration of Independence", "Press “Done” to Stop.")alert.addOption("Done")alert.show().then(index => {synthesizer.stopSpeaking(Speech.Boundary.Word)})
Shaping the Way the Text is Spoken
NOTE: The following inserted commands work only with macOS and the Alex voice.
To better control the way text is spoken by the computer, you may insert special commands into the text to be spoken. The following are two of the commands:
Emphasis Command: emph + | -
The emphasis command causes the synthesizer to speak the next word with greater or less emphasis than it is currently using. The + parameter increases emphasis and the - parameter decreases emphasis.
For example, to emphasize the word “not” in the following phrase, use the emph command as follows. Copy script and run in an Omni application Automation Console window.
Emphasis Command
function createUtterance(textToSpeak){voiceObj = voiceObj = Speech.Voice.withIdentifier("com.apple.speech.synthesis.voice.Alex") voiceRate = 0.4utterance = new Speech.Utterance(textToSpeak)utterance.voice = voiceObjutterance.rate = voiceRatereturn utterance}synthesizer = new Speech.Synthesizer()// without the emphasisutterance = createUtterance("Do not overtighten the screw.")synthesizer.speakUtterance(utterance)// with the emphasisutterance = createUtterance("[[slnc 1000]]Do [[emph +]] not [[emph -]] overtighten the screw.")synthesizer.speakUtterance(utterance)
NOTE: The emphasis control is more perceptible when used with higher quality voices.
Silence command: slnc <32BitValue>
The silence command causes the synthesizer to generate silence for the specified number of milliseconds.
You might want to insert extra silence between two sentences to allow listeners to fully absorb the meaning of the first one. Note that the precise timing of the silence will vary among synthesizers.
The Silence Command
function createUtterance(textToSpeak){voiceObj = Speech.Voice.withIdentifier("com.apple.speech.synthesis.voice.Alex") voiceRate = 0.4utterance = new Speech.Utterance(textToSpeak)utterance.voice = voiceObjutterance.rate = voiceRatereturn utterance}synthesizer = new Speech.Synthesizer()// without the silence and emphasisutterance = createUtterance("I said no!")synthesizer.speakUtterance(utterance)// with the silence and emphasisutterance = createUtterance("[[slnc 1000]]I said [[slnc 350]] [[emph +]] no! [[emph -]]")synthesizer.speakUtterance(utterance)
The Number Mode Command: [[nmbr LTRL]]…[[nmbr NORM]]
The number mode command sets the number-speaking mode of the synthesizer. The NORM parameter causes the synthesizer to speak the number 46 as “forty-six,” whereas the LTRL parameter causes the synthesizer to speak the same number as “four six.“
The Number Mode Command
function createUtterance(textToSpeak){voiceObj = Speech.Voice.withIdentifier("com.apple.speech.synthesis.voice.Alex") voiceRate = 0.4utterance = new Speech.Utterance(textToSpeak)utterance.voice = voiceObjutterance.rate = voiceRatereturn utterance}synthesizer = new Speech.Synthesizer()// without the silence and emphasisutterance = createUtterance("Please call me at extension 1990.")synthesizer.speakUtterance(utterance)// with the silence and emphasisutterance = createUtterance("[[slnc 1000]]Please call me at extension [[nmbr LTRL]] 1990 [[nmbr NORM]].")synthesizer.speakUtterance(utterance)
Archived Apple Reference Materials
prefs:root=ACCESSIBILITY&path=DISPLAY_AND_TEXT